

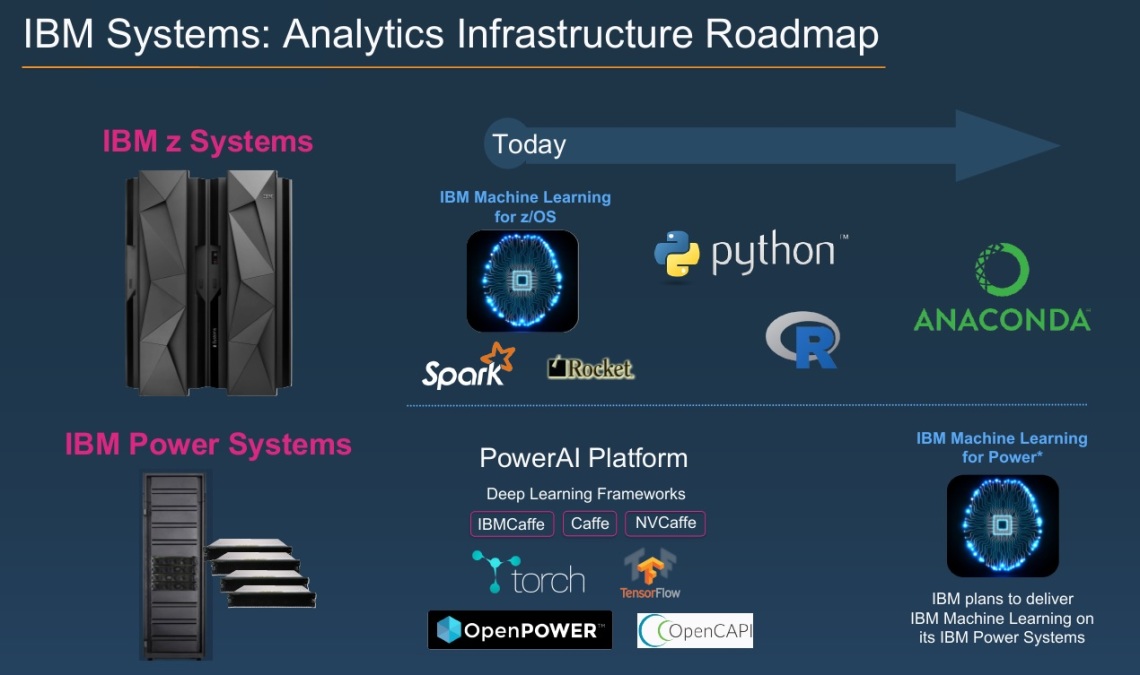
IBM Machine Learning for z/OS could be a boon to big banks and insurance companies that want advanced analytics on the mainframe. Next up is the IBM Power platform.
Public cloud providers have popularized machine learning with low-cost, easily accessible services, but that’s a separate world from the tightly regulated, on-premises computing environments maintained by many big banks and insurance companies. Now IBM is bringing cutting-edge analytics to these mainframe customers with IBM Machine Learning (IBM ML) for z/OS.
Announced February 15 in New York, IBM ML is a private-cloud-only offshoot IBM Watson Machine Learning , the public-cloud service on IBM Bluemix. More than 90 percent of data still resides in private data centers, according to IBM, and the company is in a unique position to bring the latest in analytics to these environments starting with the IBM mainframe.
Thousands of companies still rely on IBM System z mainframes, including 44 of the top 50 global banks, 10 out of 10 of the largest insurers and 90 percent of the world’s airlines. These organizations have been among the most conservative about moving their core transactional applications to new platforms. That does not mean, however, that they are not interested in taking advantage of advanced analytics.

Heretofore the likes of big banks and insurance companies have used sampling methods or batchy, bulk-data-movement to support predictive analytics. Hadoop-based data lakes, for example, are often used for customer 360 and risk analyses, and machine learning is increasingly popular in that role. But these approaches introduce data-movement costs, human-intensive manual worksteps and latency. The ideal in analytics, and the goal with IBM ML for z/OS, is to bring the analytics to the data rather than moving the data to a separate analytics environment. IBM ML for z/OS relies on an external X86 server and z Integrated Information Processors (zIIP coprocessors), so it doesn’t impact production performance or increase (expensive) mainframe processing cycles.
IBM ML for z/OS has been in beta since October, says IBM, and 20 organizations have been part of the beta program. Most of those organizations are banks and insurance companies, and many are seeking an alternative to rules-based and table-based systems that provide more primitive and brittle predictive capabilities. With machine learning applied directly to data in the mainframe environment, IBM ML promises more accurate, customer-specific prediction and, therefore, more extensive automation at the time of the transaction.
American Federal Credit Union, one IBM ML beta client, currently automates 25 percent of lending decisions while the remaining 75 percent go to underwriters. IBM says early testing for American Federal showed that IBM ML promises to automate 90 percent of the workload that would otherwise go to underwriters. Another beta customer, Argus Health, is using IBM ML for z/OS to apply and continuously update models and scores against payer, provider, and phama-benefits data in order to predict outcomes and improve the effectiveness of treatments. Banks and insurance companies have been the first in line for IBM ML for z/OS, but IBM expects airlines to use the system for applications including predictive maintenance.
IBM says it intends support analytics with a choice of languages, frameworks and platforms. At launch IBM ML for z/OS is based on Scala and uses the Spark ML library, but there are plans to support R, Python, TensorFlow and other languages and libraries. To make life easier for developers, IBM ML for z/OS includes and optimized data layer built by Rocket Software to connect to mainframe sources such as DB2, VSAM, ISM as well as non-mainframe data sources. In a demo at the announcement event, an IBMer correlated data from the cloud-based Twitter Insights service on IBM Bluemix with transactional records on the mainframe to support customer churn analysis.
IBM ML includes the company’s Cognitive Assistant for Data Science (CADS), which automates the selection of best-fit algorithms for the modeling scenario at hand. IBM’s software also includes model-management and governance capabilities that are essential in regulated environments.
Beyond adding support for more languages and machine learning libraries, the next big step for IBM ML will be support for the IBM Power platform, which also supports workload that tend to remain in private-cloud environments. IBM last November announced PowerAI Suite software for a high-performance-computing-specific IBM server that pairs Power8 chips with NVidia Graphical Processing Units (GPUs). The combination supports machine learning libraries such as Caffe, Torch, and Theano and last month added Google’s hot TensorFlow deep learning framework to the mix. IBM ML support would add CADS for automated algorithm selection as well as IBM’s model-management and governance capabilities.
MyPOV on IBM ML
It only makes sense for IBM to bring its latest analytical capabilities to System z and Power customers. Whether those customers have already turned elsewhere for predictive capabilities, and whether IBM ML for z/OS, or when available, IBM ML for Power, are better alternatives are separate questions. Analytic latency and data movement at high scale are both undesirable. But to what extent have companies already offloaded historical data from the mainframe onto lower-cost platforms? That would have a big impact on the accuracy and appeal of IBM ML. And to what extend are prospects relying on hard-to-maintain rules-or table-based systems if they’re not using more advanced forms of prediction?
Applying prediction at the transaction is clearly desirable, but companies including IBM have offered answers to this challenge before. To beat out the options already in place, IBM ML must offer lower latency, more accurate predictions, a higher level of automation, lower total cost of ownership or all of the above. IBM had a lot to say about lower latency and, through automated best-fit algorithm selection, better accuracy. We’re looking forward to conversations with early adopters to hear their take on the advantages of IBM ML over alternative routes to predictive insight.
Related Reading:
Spark Gets Faster for Streaming Analytics
Virginia Tech Fights Zika With High-Performance Prediction
NRF Big Show 2017 Spotlights Data-Driven Imperatives
