
Teradata puts Aster database on Hadoop to support ‘multi-genre’ analytics. New ‘Listener’ software collects and delivers high-volume, high-velocity data for IoT and other streaming scenarios.
Teradata is making a slew of announcements at this week’s Teradata Partners conference in Anaheim, CA, but none is more significant than the news that the Teradata Aster database will soon be available to run on Hadoop.
Teradata acquired Aster back in 2011 for its ability to handle newer, variable data types, such as clickstreams, log files and social feeds with unconventional analyses (for a database) including MapReduce and pattern and path analysis. Teradata subsequently extended Aster’s repertoire, adding support for graph analysis an in-database analytics based on the R language. Aster handles all of these analyses, as well as conventional querying, with SQL and SQL-like expressions, making it accessible to non-data scientists.
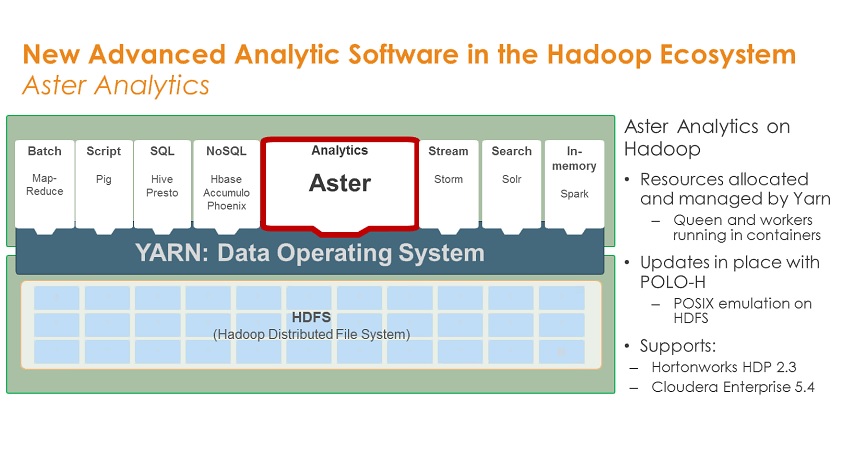
MyPOV on Aster On Hadoop. The question for Teradata customers considering Aster has always been, do I really want to run three separate platforms, assuming the Teradata data warehouse and Hadoop are also in the picture. Now that there’s an option to run Aster on Hadoop, customers won’t need to invest in, deploy and run separate infrastructure for the database. Instead, Aster will run on Hadoop clusters, with YARN as the common resource manager.
In another benefit, customers won’t need to move data from Hadoop to Aster, as the database will access the data in HDFS directly. Finally, Aster’s versatility will stand out against rival SQL-on-Hadoop offerings that focus more narrowly on conventional SQL querying. Aster on Hadoop will be available in the first quarter of next year on Teradata’s Hadoop and Unified Data Architecture appliances. Software designed to run on Hortonworks, Cloudera and other Hadoop distributions will follow soon thereafter.
‘Listen’ to Streaming Data
Among the other announcements at Partners, the company introduced Teradata Listener software for capturing and distributing streaming data. Teradata Listener is designed to work with a variety of streaming sources, including mobile apps, event-processing engines, service buses, Cassandra, Spark, social networks, and a diversity of sensors. Destination options include Teradata, Aster, Hadoop, and more.

MyPOV On Teradata Listener. This is focused software that doesn’t try to do too much. It’s not a processing engine, a service bus or integration software. Think of it as multi-point connector for streaming data. And kudos to Teradata for not overhyping the Internet of Things angle. Streaming applications come in many shapes, sizes and speeds, and connected sensors are just one of the sources Listener can capture and deliver to Teradata or Hadoop.
Running Hadoop as a Service
In one final announcement of note at Partners, Teradata announced that its Think Big consulting unit has introduced managed services for running Hadoop clusters. Given the scarcity of talent familiar with Hadoop, the idea is to speed and simplify the path to deploying and keeping Hadoop clusters up and running.
MyPOV On Hadoop services. This offering fills a clear need, but the focus of this service is on platform administrative services. The harder talent to find is data scientists. Think Big can certainly help with its consulting services for big data strategy, but these ongoing managed services won’t fill the talent gap where big data analysis is concerned.
MyPOV Overall on Teradata Partners
Teradata announced new hardware here, too, including an upgraded flagship 6800 active data warehouse platform, an upgraded extreme-capacity 1800 appliance, but it strikes me that Teradata is putting the emphasis on software and services more than ever. With revenue under pressure, Teradata is also pushing more strongly into the cloud with the offering of the Teradata database on Amazon Web Services, as announced two weeks ago at AWS re:Invent. These are all good signs, here at the 30th anniversary Partners event, that Teradata is adapting for the future.
